
Working Notes: a commonplace notebook for recording & exploring ideas.
Home. Site Map. Subscribe. More at expLog.
— Kunal
A few weeks into my sabbatical, I took another stab at vibe-coding. After a few rounds of watching agents painfully burn tokens as they wasted my time I asked Claude to reorganize my Emacs configurations.
The next thing I remember is exhausting my Claude Pro limits and upgrading to Claude Max.
My challenge with building and deploying software built by agents is a lack of trust in the generated code. I have significantly less patience for debugging agent-authored code and generally feel a sense of unease if I think about deploying it to production. There's also a nagging sense in the back of my head that I'd be much better off just implementing it myself over the long run.
With code generation being (effectively) instantaneous, my new bottleneck is being able to trust the agent's output: either by fitting it into my head or finding ways to mechanically validate correctness. I want to be involved in the design decisions, but I don't need to be involved as long as the result works correctly and efficiently.
To make this sensation concrete — something I can reason and talk about — I'm calling the complexity of the change I can make with sufficient confidence my vibe limit.
All parts of the chart are subjective, contextual and personal:
The shape of the curve between change complexity and risk depends a lot on the model and codebase it's working on:
This framing also helps me explain at least part of the discontent online: people at extremely different positions on the chart yelling past each other. The spectrum goes all the way from one-word auto-complete to Gas Town.
Something that stands out immediately is that smaller changes that can be easily vetted should be acceptable in any circumstance: this is a lesson we've learned repeatedly while reviewing code by humans, and it still stands true for code by robots.
I still haven't quite managed to ship fully agent-generated code to production: the one time I did try, I ended up ripping out and rewriting the code within a week because I really didn't want to spend time hardening and debugging generated code.
One way to have agents get more work (larger pieces of?) done without accelerating risk would be to change the shape of the risk/complexity curves. Some approaches to achieve this:
The other mechanism is to increase the appetite of risk from generated code:
Trying to approach the problem in a different way, I thought I'd compare using agent-generated code to relying on upstream libraries, or delegating the work to fellow engineers. This didn't really work out because of minimal signal on quality by default.
The reason I have trouble with agents is that I don't have a meaningful theory of mind for their behavior. LLMs exhibit jagged intelligence: brilliant in some tasks (generating python to count the number of r's in strawberry), and astonishingly incompetent in others (directly counting the number of r's in strawberry). Another phrasing I've heard that applies just as neatly is alien intelligence.
Seeing this the first few times is disconcerting: Claude (or Codex) will one shot a task that would have taken me hours or days — particularly for identifying bugs in my code — and then spin indefinitely trying to change and list directories.
Ultimately, LLMs are an extraordinarily powerful tool but the ultimate accountability for their output rests with me. For delegating to people I can consider motivation, incentives, and consequences: I have none of those for models. Which leads to a decidedly strange risk curve.
A computer can never be held accountable, therefore a computer must never make a management decision.
– IBM Training Manual, 1979 (tentatively)
Given my risk tolerance for production projects is extremely low with a correspondingly low vibe limit, my sweet spot is in quickly manufacturing tools for myself. After roughly fifteen years as a professional programmer, I heavily customize any laptops and interfaces I use to my unique preferences. Agents can become a handy shortcut to make software perfectly suited to my taste.
If the tools break, I can generally mitigate the risks by simply reverting to a known good state or even simply abandon the tool entirely.
There's also the option to design tools to be self contained and testable: flattening the risk/complexity curve and increasing the size of changes I can safely ask agents to pull off.
Tool preferences also tend to be extremely personal: a function of taste, the tools someone was first introduced to, and how people think. Leaning on the extreme programmability of Emacs — and observing smalltalk and the renaissance of moldable development — set up the frontier of customizable tools, and I'm terribly excited at the idea that everyone can build tools that fit them without having spend unreasonable amounts of time getting good at programming the tools.
The amount of effort saved is large, and helps me avoid minutiae around manipulating tools that is valuable but not essential to the actual work I want to do.
We shape our tools and our tools shape us
— John Culkin paraphrasing Marshall McLuhan
Having explicit principles felt particularly important because the tools I build here will influence what I build and how I build in the future.
I'm not particularly excited with the direction we're subtly pushed towards by the current agents where we delegate most decisions to the AIs: I would much rather be amplified by them instead.
Actually trying to build projects (see the next section for specifics) taught me a few things on interacting with agents as they are today. For now I'm exploring what works for me and don't claim to be AI-native (nor particularly aspire to it).
The frequently updating interfaces to using models, mcps, skills, swarms, etc. as well as prompt hacks feel somewhat shallow (and I expect them to be shorter lived as we rapidly iterate on models, tools, and RL to improve the models). I don't want to spend time surfing the current shape of the jagged intelligences we're working with. I plan to lean on the Lindy effect and pick things up once they've stuck for a little bit.
With all of that out of the way, my current vibe-based workflows based on a string of failures and successes in applying models:
Iterate on Design first:
Incremental commits:
CLAUDE.md (or equivalent) from the beginning.Explicitly document and commit plans and conversations:
Build in automatic feedback loops for the agent:
Build your own knowledge by inverting roles:
Have the agent one-shot the problem, delete it and restart:
Finally getting to the actual experiments I've been playing with during my sabbatical. I ended up subscribing to all of Codex, Claude, and Gemini, but most of the code here is from Claude — as you'll also see in the history from the GitHub repo.
My original problem with agentic programming was having to pass context around: i really wanted the agent to pull context from whatever I happened to be doing and the windows I had open at that point.
There was also the mechanical part of needing to support different inference endpoints (local or remote) and some way to orchestrate API calls meaningfully which I wanted to centralize for observability and key management.
Which is what led to the idea behind djinn: a set of software that could easily compose to share context, manage inference, and act as the foundation for any AI powered tools I'd build in the future. Ideally I'd bootstrap it, building djn faster and faster as I could get more tools online.
I failed miserably at this attempt.
I started by asking Codex (a few generations ago) to implement this with Python: some tmux based introspection, some emacs mcp servers, a central python server for making the calls with API support and didn't really have a fast or sane way to validate.
The agent would keep asking me for help validating the changes, and though I could play QA while streaming Netflix that felt very far from a good use of my time, and progress was minuscule.
I also ran into a different analysis paralysis: in retrospect I was asking for changes way beyond my vibe limit, and didn't quite know how to structure things so that the agents would build something I'd actually use.
After a few days I just reset the repository and decided to try much, much smaller projects instead.
With hindsight I should have started using agents to own and maintain my configurations much earlier; if you're thinking of getting your feet wet I'd strongly recommend using an agent to optimize your .zshrc or .tmuxrc.
Following Jim Meyering's advice I've been dutifully version controlling my dotfiles for several years. After a refactor I had a bit of a mess on my hands because I'd duplicated the configurations to safely update them.
To mitigate risk, I decided to do a new branch and folder for the files so I could adopt them much more incrementally.
I asked the agent to look at the previous checkout and copy changes into the new one while cleaning up any broken settings; while deleting completely obsolete configurations for software I don't use anymore.
My main prompt was to make sure changes were incrementally committed so I could easily revert breaks, but this was purely mechanical and a great warmup.
You can compare the before and after on GitHub.
I'd generally recommend giving your dotfile management over to a model; just remember to move your API keys into a separate file first.
Along the way, I was somewhat dissatisfied with the color schemes I had available on WezTerm (and browsing through all 1,000 options gets monotonous) so I asked Claude to whip up a light theme based on Cosmic Latte as the background color.
Then, obviously, the next step was a dark theme that complemented it. The moment of joy was Claude calling the dark variant Cosmic Espresso.
This was another excellent experience: color schemes can be personalized a lot and not having to learn the syntax/format for each different tool goes a long way. After Poet I haven't wanted to maintain my own, but I can easily see myself build themes around paintings and photographs.
My Emacs configuration is generally split into a default init.el and a local.el for laptop-specific configurations. I decided I wanted to be able to have models live modify these configurations, and broke them out separately from the dotfiles.
Accordingly I ended up forking a new GitHub repository and local folder: again, I wanted to make sure I could keep working even if my Emacs configuration broke in strange ways, I had a backup so I set up a new configuration folder at $XDG_CONFIG_HOME/.aiemacs. Instead of relying on my regular wrappers (e, en to launch Emacs client or standalone Emacs, respectively) I ended up using some custom wrappers to launch standalone and emacs client instances with the new config folder.
(I'm keeping AI-generated Emacs configurations private for now: I'm not entirely certain I'd catch it if something sensitive leaked into the configurations. So you'll find more gists and snippets in this section instead.)
My configurations have grown (cough) organically: I had different settings for Python, languages, and different modes spread out somewhat randomly. The first step was to have Claude reorganize everything and make sure I could version control it: that way I can get incremental updates without having to go all the way back to my original configurations (even though I still maintain that nuclear option).
Claude cleaned up all of my configurations, collected them into init.el; I'd also been introduced to straight.el because of vterm and leaned into it to get fully reproducible configurations. (It relies explicitly on the committed configuration and doesn't allow for package-install packages to be saved.)
To further reduce the amount of context required to make incremental changes and add features, I had Claude refactor all the small plugins baked into my existing configuration (eg. for desaturating a color scheme) and make them into separate version controlled pieces.
With all of that preparation in place I've been an order of magnitude more comfortable with Claude modifying and extending my emacs configurations.
I wanted to be able to trivially use agents from within Emacs: Agent Shell that relies on Zed's Agent Client Protocol is excellent, but I really wanted it to be trivial to give the agent context based on the my current files and position.
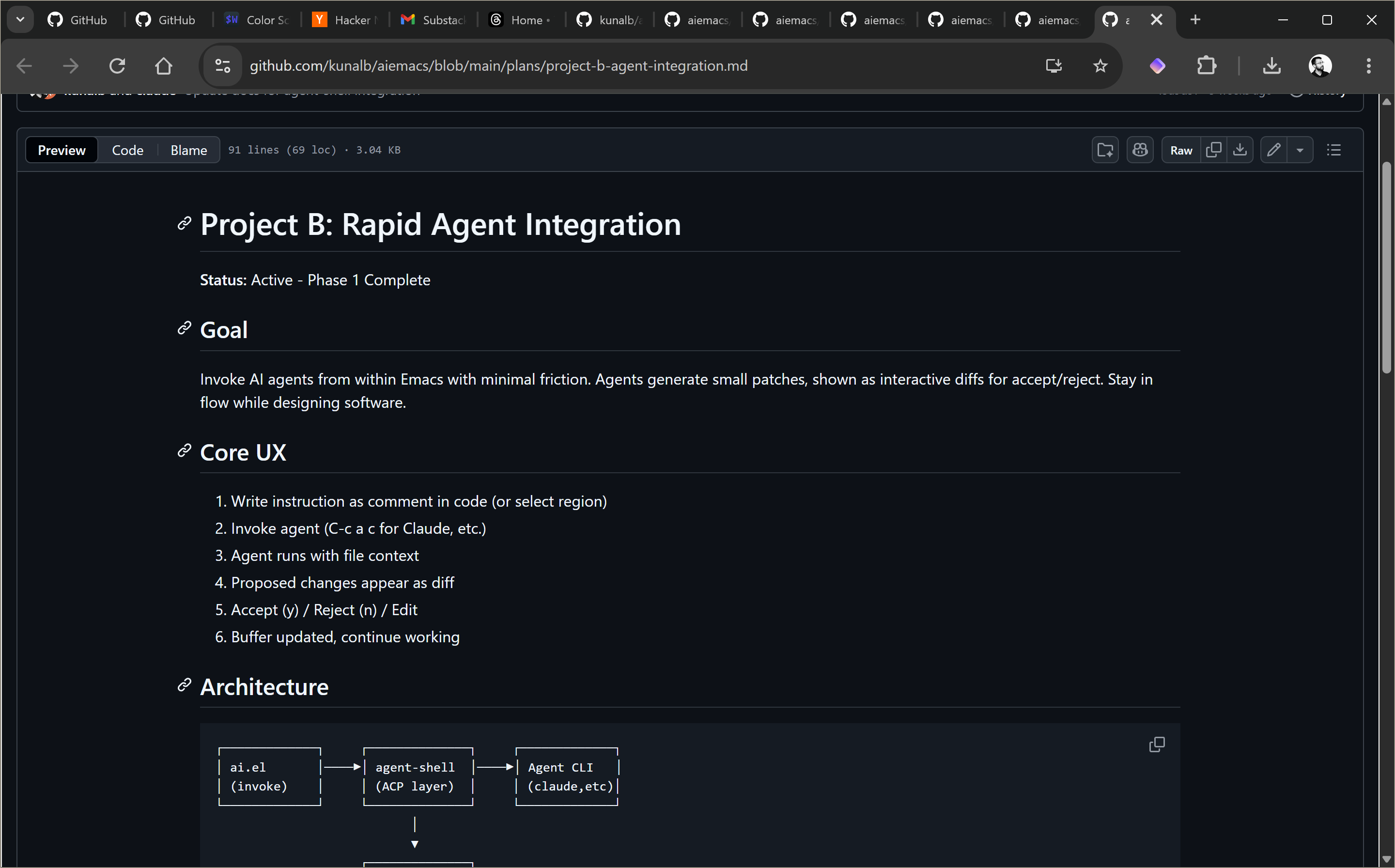
Claude whipped up a small plugin that makes it trivial to launch into an agent session using C-c a c: I can enter some instructions and immediately get back to whatever I was working on. Grab the plugin here: ai.el.
You can see Claude sanity-check this file as an example:
This has been really helpful in making extremely targeted changes that I can apply regardless of how critical the code I happen to be working on, while maintaining full personal context.
A fun additional use case I have with this workflow is to drop into my Emacs config with C-c e i and ask Claude to add a new keyboard shortcut or customize behavior and it Just Works. (And, of course, I used Claude to add that shortcut to my configuration.)
exec)Agents and UIs often feel incredibly heavyweight when I need to figure out the right flags for a quick command (it's almost always git, of course), but that also feels like the single most tractable problem for agents to solve for me with sophistication.
My desired workflow is that I can just type out a command in English, and get a model to convert it into something that just works that I can then run trivially. I've made several iterations of this tool with different backends, generally with direct API calls.
This time around I had Claude make something slightly different:
Ctrl-R) and modify the generated commandIn practice, agent startup times are fairly bad (all that JavaScript); enough that I had Claude profile and give me some estimates: this was a fascinating exercise in itself with the output captured here.
For now, I'm just having it default to codex for these commands, but there are obvious solutions to working around this (either maintaining long-running agent sessions, or eating the cost of maintaining API keys explicitly).
With the standard caveats to pay attention to your personal vibe limit and that I haven't vetted this code carefully, you can install it with:
cargo install --git https://github.com/kunalb/djn x
I need to give some context on this one, but if you're impatient you can go and directly play with it here.
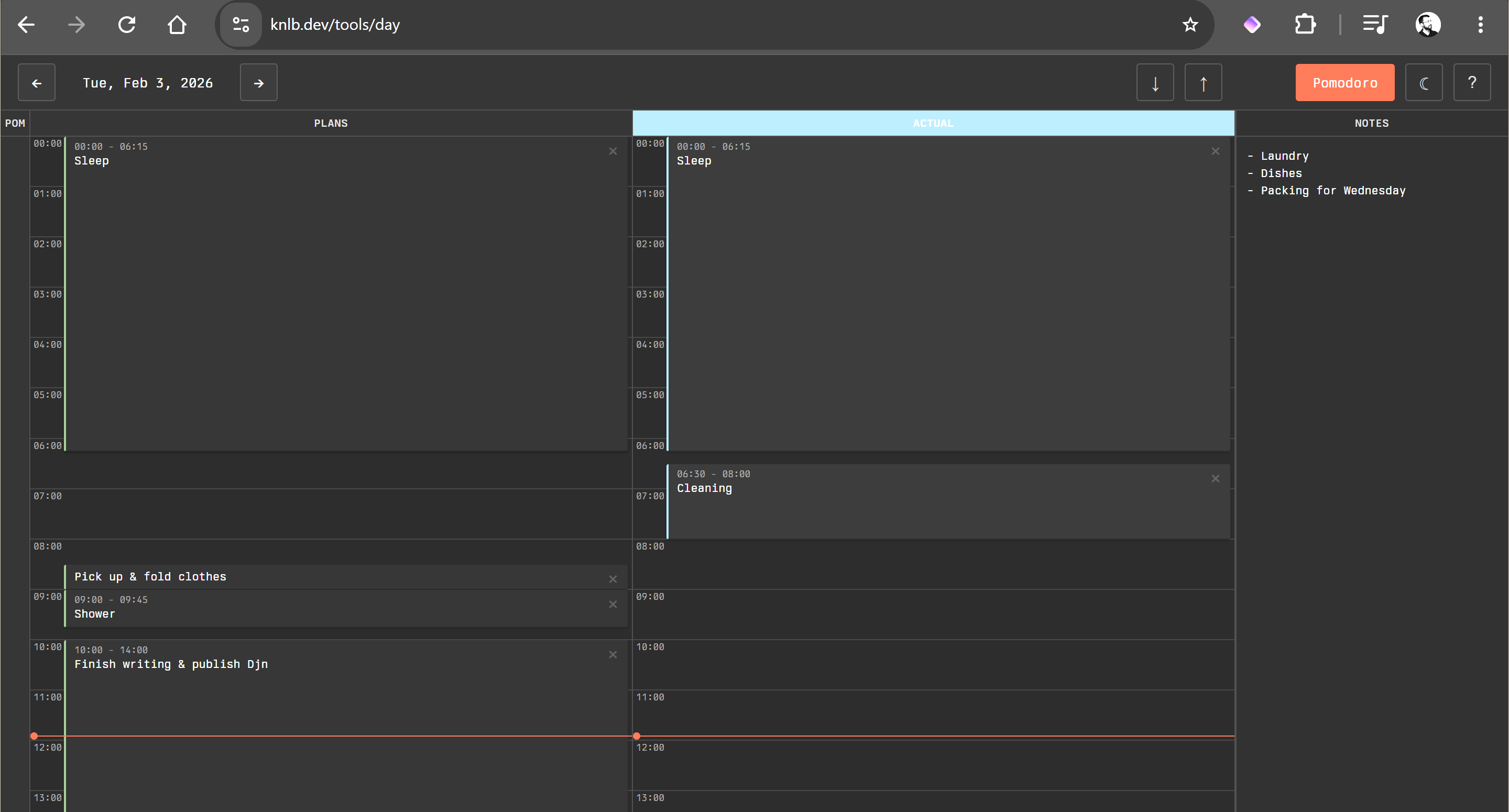
For the past several years I've been using Stalogy Editor notebooks to map out my day. Each page has a 24-hour grid on the side, and the notebooks are sized to last for either half a year or a full year; I'm on my third notebook at this point. The way I like to use them is to:
I lean on this heavily when I have a lot going on and need to be precise; the freedom of sketching on paper also works really well while I'm traveling and I can draw things based on my perceived time without having to constantly configure time zones.
Single-page HTML applications can be really powerful and simple: extremely self contained, and can even access files on disk with specific Chrome API's and permissions.
As an explicit design choice I prefer to build these with plain old JavaScript (both before and after the availability of coding agents), and Claude quickly built an equivalent of my workflow with just 2000 lines (HTML, CSS, and JavaScript included).
This experiment is one of the places where I couldn't get Claude to test what it was doing and it shows: there are still several annoying glitches with small touch areas throughout the UI, though the design itself matches my tastes well. At this point it's good enough for me to use, but not something I'd recommend to others. I've been through several iterations, and generally feel as if I'm approaching the limit at which point I'd be better off digging into the code and fixing it myself.
There are several more (surprisingly alliterative) projects that I've been prototyping but won't get into here: Palimpsest, for doing code archaeology on files and commits rapidly so I can see how a specific function evolved; Planner, for something that's like FocalBoard but with a few more features I wanted, Polyptych, for generating Perfetto traces dynamically — I'm connecting it with DuckDB to have a lot of data sources just work. This is going to be an attempt at making production software with vibe-coding, and I need to devote a lot more time to it.
It's hard to write about AI without addressing the flashing neon elephant in our collective, virtual drawing room: "Software Engineering is dead", "There will no longer be any jobs", "Coding is meaningless as a career", "100x engineers", and so on and so forth.
Belonging to the tribe of programmers has always meant signing up for a lifetime of learning; AI happens to be one more step, and one that gives us a lot more leverage. We can learn much more rapidly, work in unfamiliar contexts that much faster.
Things will change, perhaps rapidly; but not entirely overnight: see Dario's note on Machines of Loving Grace: the consequences of AI adoption are still limited by physics and human behavior, which can only move so fast. We'll have time to adapt and learn.[2]
The better AI becomes, the easier it will be to adopt by definition. Surfing at the frontier can be fascinating — and can open opportunities for the entrepreneurial — but it isn't necessary.
There are several well-thought-through documents on using AI tools within organizations: Oxide's RFD on LLM usage, and Monarch's philosophy on AI use — particularly the emphasis on accountability. Isometric.nyc is an example of something that I don't think would exist without AI.
I'm optimistic about intentionally applying AI to magnify my effectiveness across different domains and becoming able to build and learn things I never would have been able to otherwise; I'm pessimistic about the consequences of the hype cycle around it, particularly those that lead to sudden catastrophic failures once complexity compounds in vibe-coded systems.
The tools still have a very long way to go for me: to start, I really don't want to have to give context to the models anymore and would love for it to be trivially fetched based on what I'm doing on the computer. Djn was supposed to help enable this; while I ended up deleting the first vibe-coded attempt, I plan to resurrect it soon.
The second thing I would like to see is getting much better at managing the complexity generated by applying agents; the Agent-in-IDE / UI interfaces do this, but I think there are more interfaces possible to orchestrate and engage with agents in a way that enhances trust and pushes my vibe limit forward.
Being able to understand and navigate someone else's vibe-coded output (preferably with the original dialogue) will become increasingly critical to manage complexity, and something that seems entirely under-served.
A new bottleneck I expect to see as it becomes much easier to build software is to distribute it. Relying on the browser — or phone OS — as a sandbox and making it trivial to share applications should unlock a lot of creativity and value.
At the consumer end, it becomes incredibly difficult to understand what's actually worth using: mobile stores already suffer from clones and poorly executed copies, I can only expect that problem to compound significantly.
My intuition suggests that open source software that was already built to be customized: Emacs, (Neo)Vim, SmallTalk, Moldable Development, the suckless suite should work really well with agents. Trivially updated, rebuilt and easily sanity checked, with lots of examples available.
A dream I have about the future of software is that the idea of applications disappears entirely; instead we can express our intent — just by talking to the machine — and get something perfectly suited to the hardware it runs on and the person actually using it.
Email me, Threads, Twitter or Hacker News.
I explicitly call it complexity instead of size because lines of code only occasionally maps to complexity. Large changes can sometimes be extremely simple, mechanical codemods: a direct search and replace; small changes can trigger catastrophic performance failures. ↩︎
The economic consequences are currently beyond my ability to predict: I'm fairly curious about how things change as inference becomes less subsidized, and at the same time technology and hardware improves to make it cheaper regardless. Working out the tokenomics — including physical resources — is something I'll leave to SemiAnalysis. ↩︎